Оглавление:
- 1 Шаг 1. Чистка семантического ядра по словам-маркерам
- 2 Шаг 2. Удаление повторяющихся слов
- 3 Шаг 3. Удаление латинских букв, специальных символов, запросов с цифрами
- 4 Шаг 4. Чистка с помощью стоп-слов
- 5 Шаг 5. Чистим ядро с помощью функции анализа группы слов
- 6 Шаг 6. Ищем и удаляем неявные дубли
- 7 Шаг 7. Ручной поиск по группе запросов
- 8 Шаг 8. Очистка запросов по частотности
- 9 Вместо заключения
Статья последний раз была обновлена 05.06.2023
Подразумеваем, что семантическое ядро уже собрано, и перед тем как разделить запросы по категориям, их следует хорошенько почистить. Как убрать восемь уровней шлака и оставить чистое серебро? Понадобится программа Key Collector и 12 минут на прочтение этого поста.
Шаг 1. Чистка семантического ядра по словам-маркерам
Открываем Key Collector и с помощью фильтра отсеиваем все неподходящие слова. Например, для категории «серебряные кольца» основными маркерными словами будут «серебряные», «кольца», а также их словоформы. Вписываем только часть слова, чтобы охватить все словоформы.
В первую очередь отберем все запросы без «кол-» в Key Collector. Для этого переходим на вкладку с выбором условий фильтраций. И выбираем соответствующие условия (фраза не содержит «кол-»).
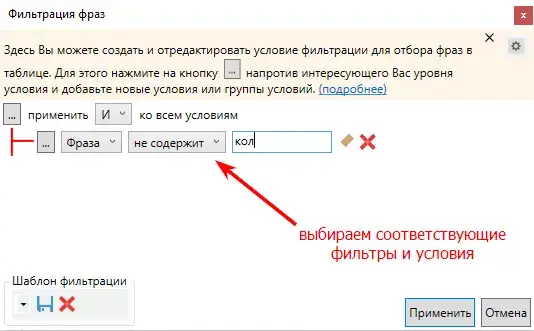
Отмечаем все отфильтрованные фразы и отправляем в «корзину».
Дальше по такому же алгоритму отфильтруем запросы по слову «серебр-».
Чтобы охватить больше фраз с одинаковым значением, в Key Collector существует возможность создавать вложенные фильтры.
Для чего это нужно? Например, возьмем запросы «кулоны» и «подвески». Оба варианта в выдаче будут показывать идентичные результаты.
В данном примере мы выполнили поиск информационных запросов, содержащих слова «кулон» и «подвеска».
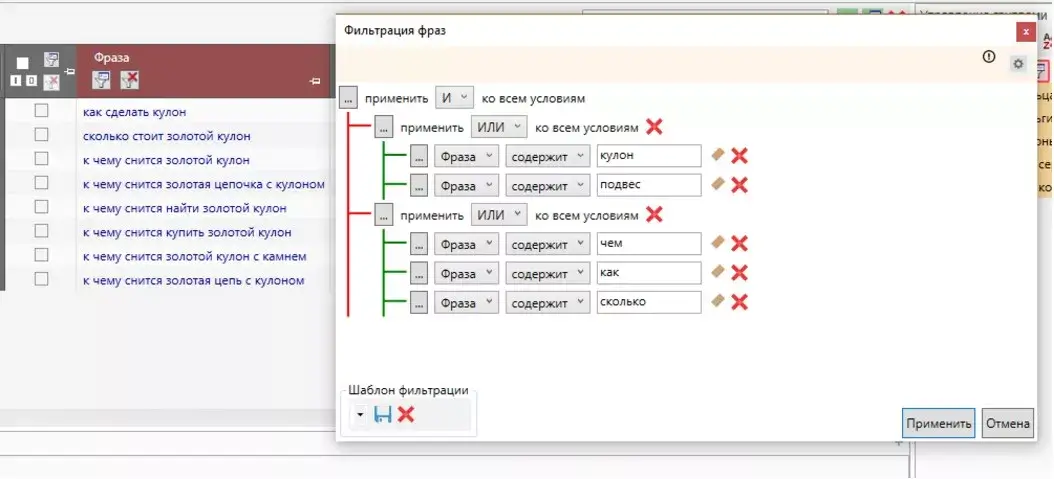
Все созданные фильтры по заданным условиям можно сохранять и использовать в других проектах. Как это сделать?
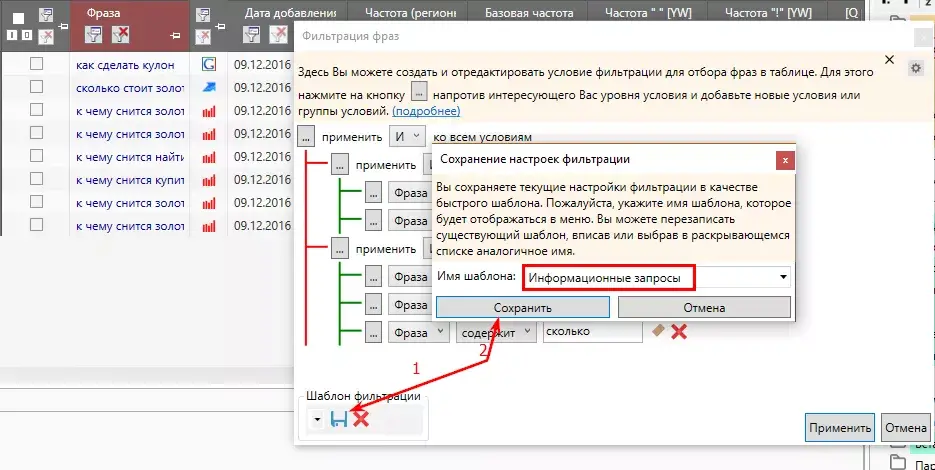
Шаг 2. Удаление повторяющихся слов
Фразы с повторами зачастую мусорные, поэтому имеет смысл удалить их уже на первых этапах чистки семантики. Для этого выбираем расширенный фильтр и настраиваем правило: «Фраза» — «Содержит повторы слов».
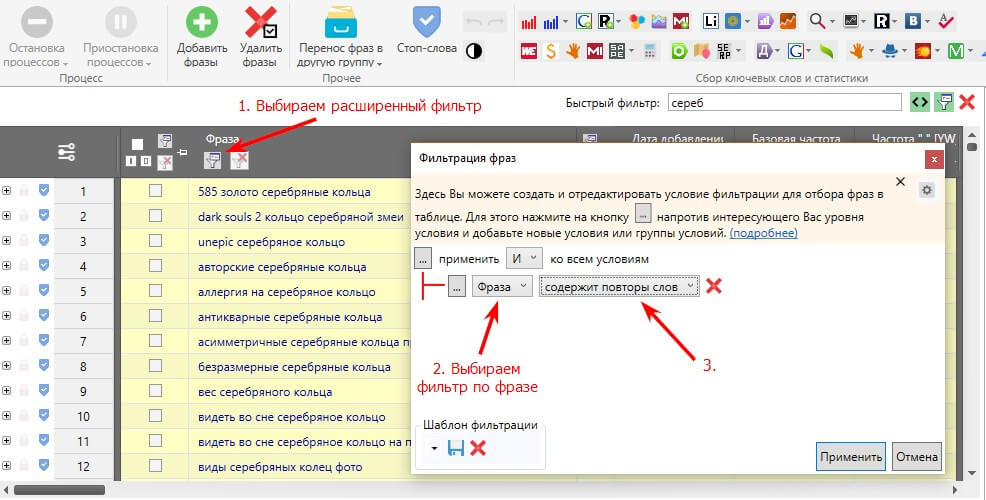
Шаг 3. Удаление латинских букв, специальных символов, запросов с цифрами
Удалить латинские буквы и спецсимволы можно с помощью:
- расширенного фильтра,
- регулярных выражений.
С помощью расширенного фильтра можно выбрать сразу несколько параметров.
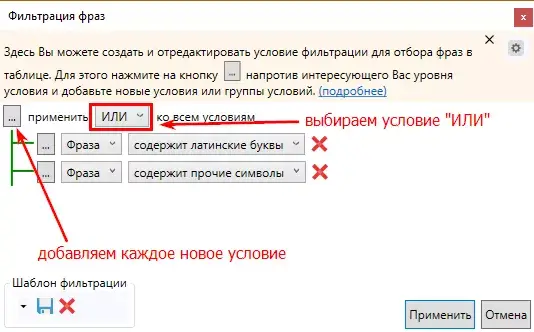
Фильтр по условию «содержит прочие символы» выберет фразы с украинскими символами «і», «ї».
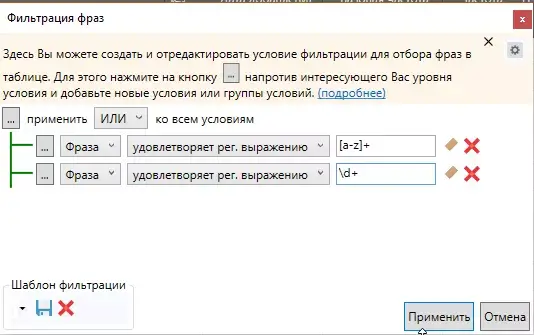
Не забывайте применить правило ИЛИ/И ко всем условиям.
Другой метод — изучить регулярные выражения и очистить семантическое ядро с их помощью.
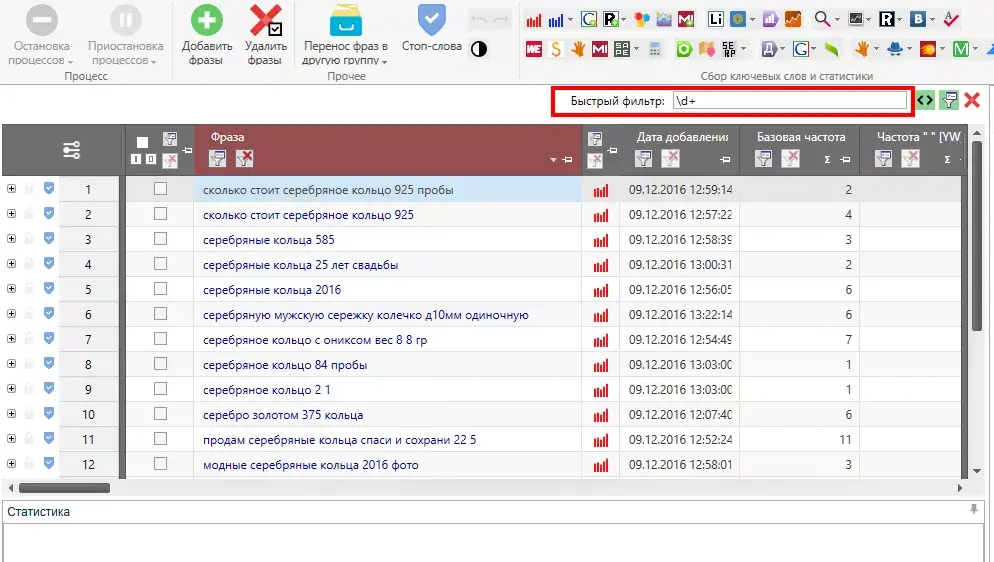
Регулярное выражение \d+ помогает избавиться от цифр.
Например, в случае семантического ядра по серебряным кольцам я оставляла все запросы, содержащие значение пробы металла и веса изделия, но удаляла год выпуска.
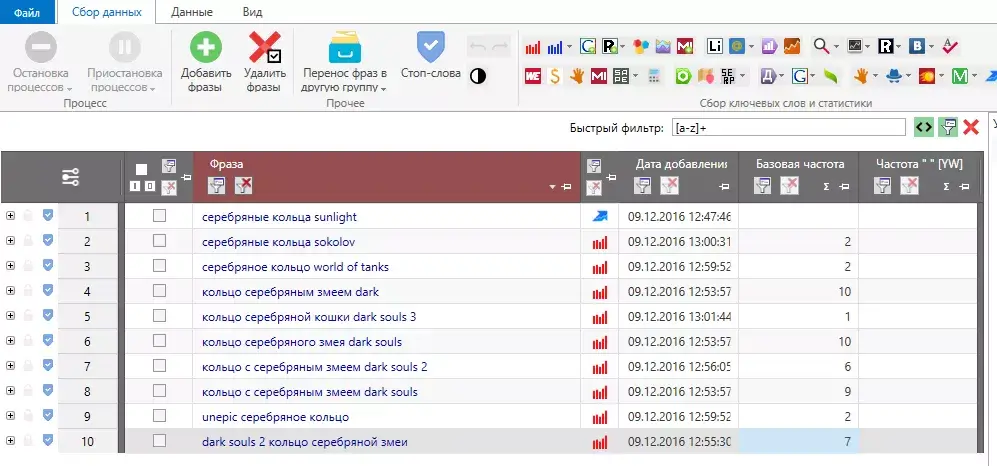
Регулярное выражение [a-z]+ нужно для фильтрации букв латинского алфавита.
Буквы латинского алфавита могут быть в названиях брендов, коллекций или других элементов карточек товаров. Перед удалением таких запросов советую внимательно их просмотреть.
Фильтрацию с помощью регулярных выражений можно проводить и с помощью быстрого фильтра (как на примере выше), и с помощью расширенного фильтра.
Шаг 4. Чистка с помощью стоп-слов
Переходим на вкладку «Стоп-слова». Добавляем слова, которые нам не нужны. Обычно я делю все стоп-слова на несколько групп:
- информационные;
- города (которые не соответствуют маркетинговым целям);
- все, что относится к бесплатным способам получения товара: бесплатно, недорого, дешево, дорого, на/под заказ (не для всех сайтов) и т. д.;
- субъективные понятия: самый, лучший, красивый, необычный, прикольный, оригинальный;
- названия сайтов с объявлениями: «авито», «юла» и пр.;
- визуализация: изображения, фото, видео, скачать, смотреть, чертежи, инструкции, схемы;
- очень часто встречаются запросы с приставкой «своими руками», их тоже добавляем в стоп-слова.
Список групп может варьироваться в зависимости от тематики сайта, но приведенные выше примеры работают практически во всех случаях.
Важно! Информационные запросы с приставками «как», «где», «что» советую не удалять. Лучше перенести их в отдельную папку и в будущем использовать для разработки контент-плана.
Также можно все ненужные слова добавлять непосредственно из полного списка запросов. В таком случае создаем отдельную группу — специально для таких стоп-слов. Кликаем на значок слева от нерелевантного запроса, в открывшемся окне выбираем, что добавить в список стоп-слов.
Шаг 5. Чистим ядро с помощью функции анализа группы слов
В KeyCollector переходим на вкладку «Данные» — «Анализ групп». Отмечаем группы со словами, которые не подходят.
Группы, отмеченные в таблице, автоматически отмечаются в основном списке запросов. После того как были отмечены все неподходящие слова, закрываем таблицу и удаляем все ненужные запросы.
Шаг 6. Ищем и удаляем неявные дубли
Для использования данного метода необходимо сначала собрать информацию о частотности запросов. После этого переходим на вкладку «Данные» — «Анализ неявных дублей». Выделяем необходимые настройки и нажимаем кнопку «Умная отметка». Программа автоматически отметит все неявные дубли, частотность которых меньше в указанной поисковой системе.
Шаг 7. Ручной поиск по группе запросов
Наконец можно отметить вручную все ненужные слова в семантическом ядре: сленг, слова с ошибками и так далее. Основной массив нерелевантных запросов уже был очищен ранее, так что ручная чистка не займет много времени.
Шаг 8. Очистка запросов по частотности
С помощью расширенного фильтра в KeyCollector устанавливаем параметры частоты запросов и отмечаем все низкочастотные фразы. Этот этап нужен далеко не всегда.
Эти шаги далеко не исчерпывающее руководство по фильтрации собранных поисковых запросов, для еще большей глубины проработки ядра можно почитать вот эту статью от какой-то студии (не реклама).
Вместо заключения
В фильтрации семантического ядра можно пойти вообще другим путем — провести кластеризацию запросов на первой же стадии после сбора. Не рекомендую использовать сервисы вроде Serpstat при таком подходе, ибо ядро станет в копеечку, лучше использовать программы вроде KeyAssort. Есть статья по настройке кластеризатора KeyAssort.
Из тех слов, которые не подходят ни в один кластер, можно сформировать отдельную группу в KeyCollector. Также вы сами можете редактировать и чистить уже готовые кластеры.
Существуют разные подходы, потому что работа с семядром — это творчество!

Кандидат технических наук, доцент кафедры ИУ-6 (Компьютерные системы и сети) Московского государственного технического университета им. Н. Э. Баумана. Самый молодой в России PhD in Computer Science. Эксперт в области компьютерных технологий и программирования.
Стаж: 8 лет.
Образование: МГТУ им. Н. Э. Баумана, к.т.н.
- Как узнать IP-адрес по MAC-адресу - 07.04.2023
- Пинг проходит, а страницы в браузере не открываются - 07.04.2023
- Что если сайт пингуется «извне», но не открывается из под «локалки»? - 07.04.2023