Оглавление:
Рано или поздно любому вебмастеру потребуется скачать какой-то сайт с вебархива. Цели бывают разные, от получения забытого поисковиками и типо уникального контента, до полного копирования сайта с сохранением всей страктуры, для восстановления на приобретенном дроп-домене. Лучше всего для этого подойдет бесплатный сервис web.archive.org. У сервиса нет никаких квот на объемы данных и время скачивания. Нам потребуется только терминал и 5 минут на настройку. Все манипуляции будут производиться в операционной системе Windows пусть 10.
Установка Ruby
Поддержка Ruby в системе необходима для работы нашей утилиты для скачивания сайтов с вебархива. Установить проще всего дистрибутивно, то есть зайти на сайт этого языка программирования и скачать инсталлятор. Все должно установиться автоматически, включая переменные окружения, и по итогу Ruby вот так мило встанет на диск C:
Установка Wayback Machine Downloader
Это и есть наша бесплатная консольная утилита для скачивания архивной версии сайта. Устанавливать мы ее будем через встроенный в Ruby пакетный менеджер RubyGems, вот такой командой:
gem install wayback_machine_downloader
У меня эта программа уже установлена:
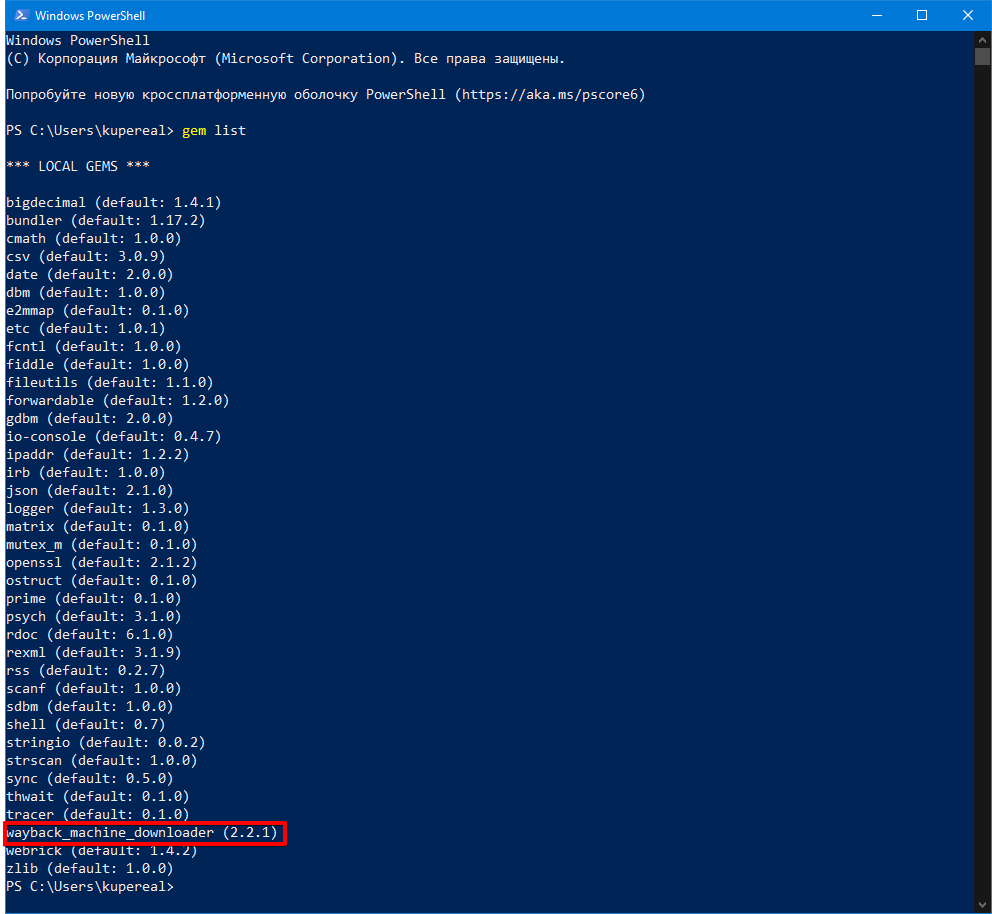
И теперь переходим к самому главному!
Качаем сайт с веб-архива бесплатно
В терминале вводим команду:
wayback_machine_downloader https://site.com
Где https://site.com — любой сайт, который нужно скачать (сайт можно указать и без протокола). Оговорка, почти любой. Некоторые сайты закрывают доступ боту вебархива в robots.txt и не сканируются сервисом, также владельцы сайта могут попросить удалить все снимки своего сайта, и это будет выполнено безоговорочно администрацией Wayback Machine.
Дополнительные параметры утилиты можно посмотреть на ее старнице в GitHub (см. ссылку выше по тексту).
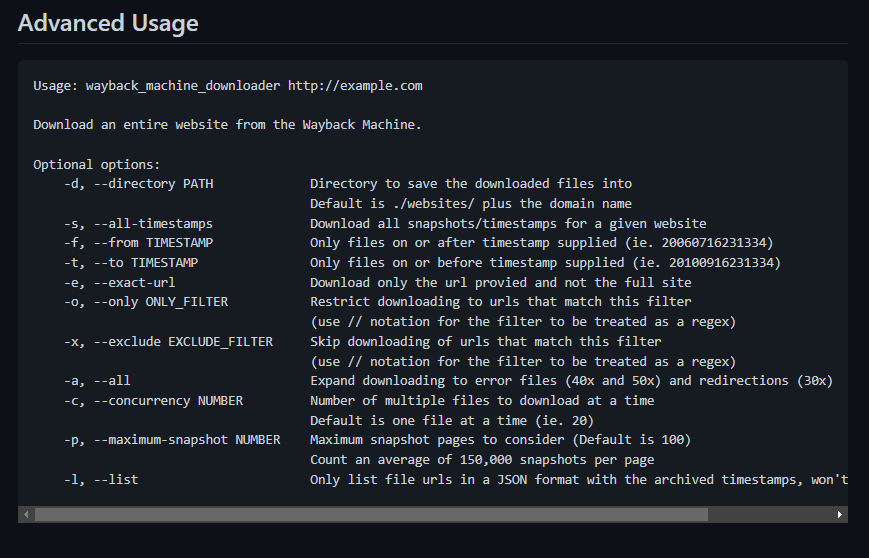
Для понимания, как пользоваться дополнительными параметрами, приведу пример. Ситуация такая, что сайт обновлялся только до определенной даты, а потом домен был припаркован. Значит нам нужно скачать сайт только до определенной даты, чтобы не скачивать мусорные страницы из снимков архива. Для наглядности проще всего посмотреть эти моменты на сайте веб-архива:

Это значение в URL — 20150214182119 называется TIMESTAMP, теперь мы можем использовать его в параметрах утилиты для скачивания старого сайта. Вот так:
wayback_machine_downloader https://site.com --to 20150214182119
Еще одна важная опция. Если скачиваемый сайт огромен, то нужно скачивать его не постранично, а, например, по 20 страниц за один подход:
wayback_machine_downloader https://site.com --to 20150214182119 --concurrency 20
Результат
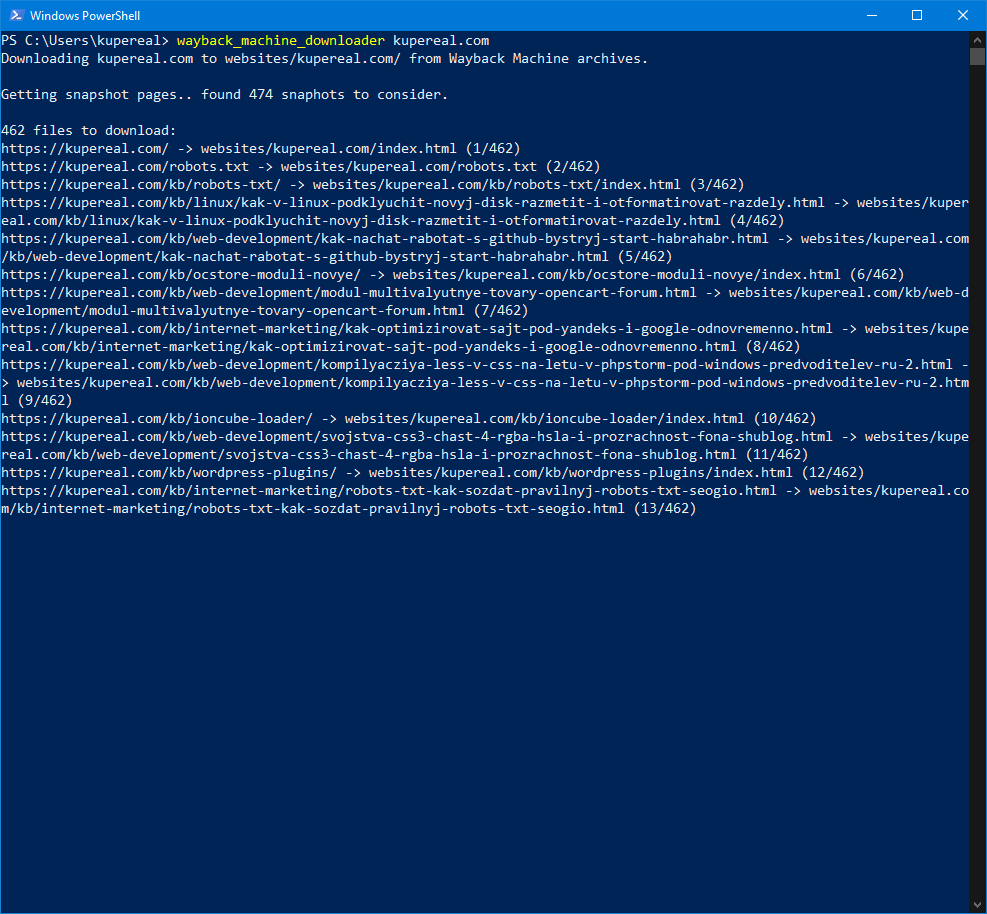
Отменить процесс можно нажав Ctrl+C. Все сайты по умолчанию будут скачиваться в папку websites в профиле пользователя.
Скачиваться сайт будет в HTML формате, с сохранением структуры катологов, все внутренние ссылки тоже будут работать. По сути, это не просто скачивание архива сайта, а создание готового статического сайта на файлах, который потом можно выгружать на любой хостинг. Если вы планируете размещать статические сайты массово, то лучше выбрать хостинг с раздельной оплатой за сервисы, когда например можно оплачивать только наличие веб-сервера Apache и не платить за интерпретатор PHP или поддержку СУБД MySQL. Как вариант, можно использовать бесплатные площадки для подобных сайтов типа GitHub Pages или Cloudflare Pages. Но это уже отдельная история…
Спасибо большое!! Вы просто спасение! Так всё четко сработало и без всяких ошибок! Вы так понятно и просто всё объяснили!
Сложно было только найти папку, куда это всё закачалось.
От души! Благодарю!!!!!
Спасибо за инструкцию, только скрипт этот больше не работает. Я нашел рабочий форк: https://github.com/birbwatcher/wayback-machine-downloader, работает он точно также
Да, автор забросил свое детище, но у проекта на сегодняшний день 792 форка! Вот самый свежий и залайканный: https://github.com/StrawberryMaster/wayback-machine-downloader