Как осуществлять непосредственно кластеризацию, группирование поисковых запросов, я рассказывать не буду, в этом посте просто набор скринов с настройками моего приложения KeyAssort.
Раньше я всегда ориентировался на простую человеческую логику, но поисковые алгоритмы усложнились, особенно по части НЧ и супер НЧ запросов, люди стали вбивать целые предложения в поисковую строку. Сперва я начал использовать сервис Just-Magic, но если загружать туда огромное семядро без предварительной фильтрации, то по затратам оно станет просто золотым.
Конечно, если вы из тех интернет-маркетологов, кто собирает ядра по вордстату с каким-то убогим плагином для хрома, о котором рассказывает каждый дилетант на ютубе, то у вас и не получится 10k запросов чисто физически. Если собирать ядра из многих источников по широкому кругу соответствий, то фильтровать это все до группировки достаточно уныло. Гораздо проще сразу получить релевантные и семантичные группы запросов с достаточным трафиком, чтобы не попасть под «мало показов» в Яндекс.Директе, а потом уже фильтровать их в самом Директе, разбираться с хвостом оставшихся запросов.
Как вы уже поняли, при таком принципе работы, рассчитаном на автоматику, а не «колупание» вордстата с мозговыми штурмами наперевес, необходимы хорошие мощности для массовой обработки запросов. KeyAssort в этом вопросе молодец.
Итак, первый скрин. Не знаю конкретно, что я тут менял, но зачем-то решил сохранить.
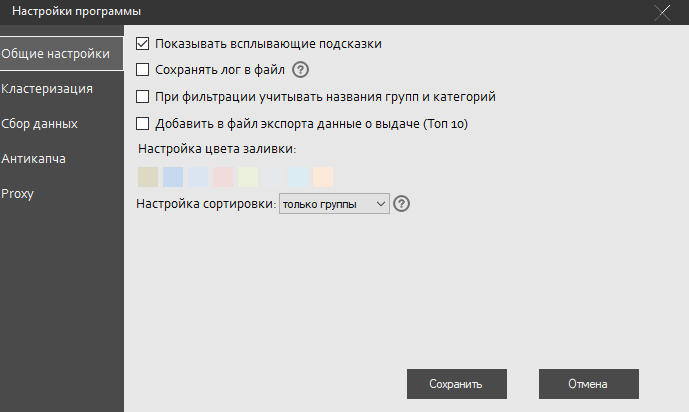
Второй скрин. Это уже глобальная тема. Прелесть программы в том, что можно пробовать и так и этак различные параметры кластеризации. Можно выбирать методы: Hard, Middle, Soft. Играться с силой группировки. Описывать каждый параметр нет никакого смысла, этими изысканиями забит весь интернет, каждому нужно просто попробовать разные режимы и посмотреть, что из этого получиться.
Я выбрал для себя такие параметры, ибо мне нужны «железные» соответствия запросов, чтобы не лить трафик на «левые» сущности. Если вы делаете группировку для SEO, то можно ослабить созависимость (3-5) и упростить метод (Medium), потому что вы сможете попасть по этим запросам в выдачу, не обязательно в ТОПы, а можете и не попасть, этот трафик не будет напрямую оплачиваться как в контексте.
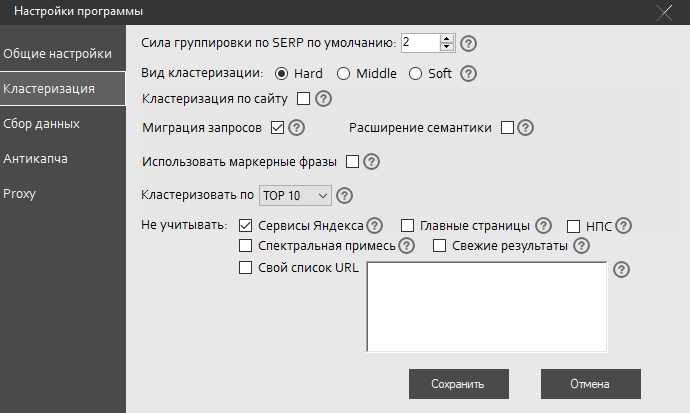
Третий скрин. Я уже говорил, что собирал кластеры под Яндекс.Директ. Учтите, для работы программы необходимы XML лимиты!
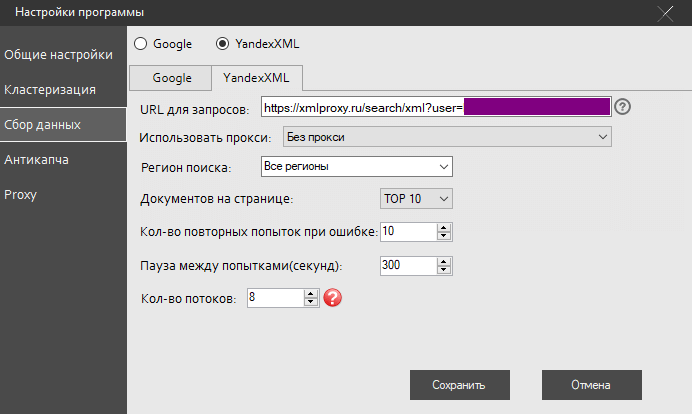
Четвертый скрин будет последним, потому что последнюю вкладку настроек, связанную с PROXY, я вообще не трогал. Без антикапчи в программе тоже никуда, но это сущие копейки, как и в случае с XML лимитами.
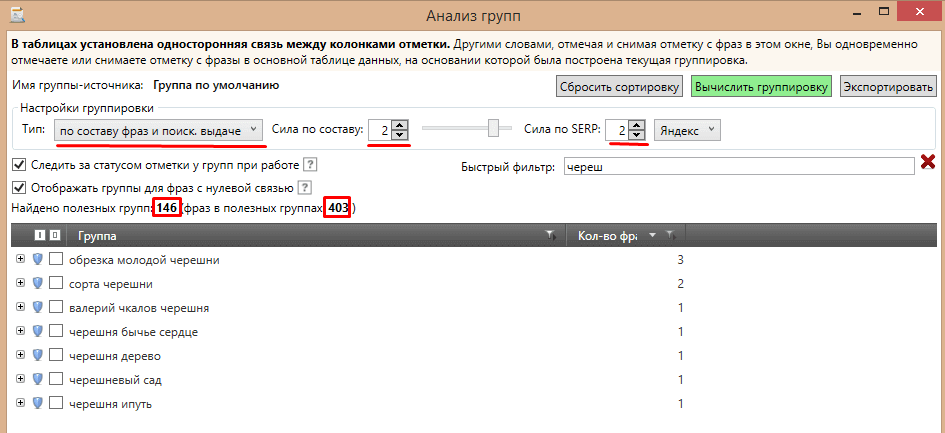
Анализ групп в Key Collector
Программа другая, но тема та же, поэтому решил добавить сюда еще пару скринов. В Key Collector 3 (скрины от него) тоже есть возможность группировать запросы.
Первый скрин — простая группировка.
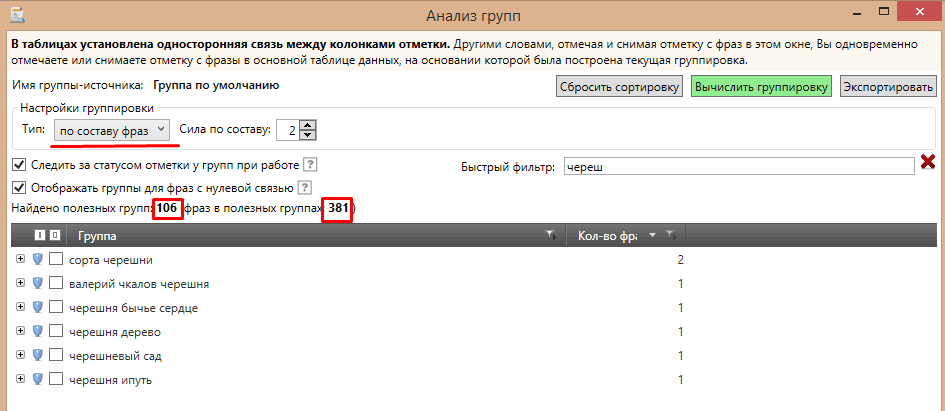
Второй скрин — группировка + KEI.